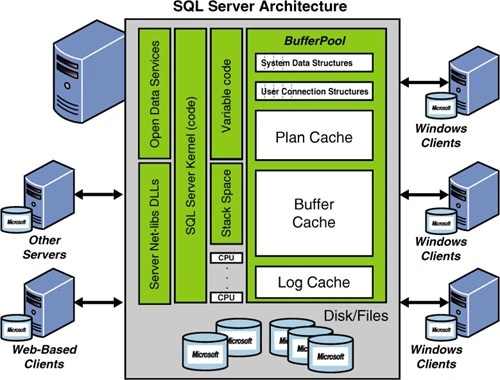
| Event Loop | The event loop is single-threaded. node automatically starts, this makes the asychronous programming loop possible. |
| JavaScript VM | forked process, can use multiple threads |
| The Call Stack | FIFO |
| REPL | Read, Eval, Print, Loop |
| package-lock.json | describes an explicit dependency manifest, meaning that other developers (and CI) are able to install exactly the same dependency tree. |
| libuv | This library provides Node.js with the event loop. libuv is Cross-platform I/O abstraction library that supports asynchronous I/O based on event loops. It is written in C and released under MIT Licence. |
| core module: async_hooks | provides an API to register callbacks to track asynchronous resources created inside a Node.js application |
| Self-Referencing relationship | A self-referencing relationship (or recursive relationship) in a relational database occurs when a table's foreign key column references the primary key of the same table, which is used to model hierarchical or recursive data structures where records are related to other records of the same type. |
| deadlock | occurs when two processes each have their own transaction trying to update two rows of data but in the opposite order |
| Data passing methods | Data passing methods, also known as parameter passing or argument passing, are evaluation strategies that dictate how arguments (data) are transferred from a calling routine (like a function or method) to a called routine, primarily categorized as pass-by-value (transferring a copy of the data) or pass-by-reference (transferring a memory address/reference to the original data). |
| Data Transfer Object (DTOs) | A Data Transfer Object (DTO) is a design pattern used to transfer data between subsystems of an application, often containing minimal to no business logic, serving primarily as a container for data. |
| Data Cleaning (Data Scrubbing) | Data cleaning (or scrubbing) is the process of detecting and correcting (or removing) corrupt, inaccurate, or irrelevant data from a dataset. |
| Data Reconciliation | Data Reconciliation is the process of ensuring that data from two or more sources is accurate, consistent, and aligned. It involves comparing datasets to identify and resolve discrepancies, ensuring data integrity and reliability. |
| Low-Level Binding | refers to directly interacting with the database using raw SQL queries. This approach gives you fine-grained control over your data operations and is often more performant because you can optimize your queries specifically for your use case. However, it can also lead to more complex code, as you'll need to handle SQL syntax, parameter binding, and potential SQL injection vulnerabilities manually. |
| ORM | is a programming technique used to convert data between incompatible type systems in object-oriented programming languages. An ORM allows developers to interact with the database using high-level programming constructs (like classes and methods) rather than writing raw SQL queries. This can simplify data manipulation and improve code maintainability. |
| query | |
| Data Model | a conceptual representation of how data is structured, organized, and related within a database or information system. |
| data pipeline | |
| data cleaning / cleansing / scrubbing | Data cleaning or appending is the procedure of correcting or removing inaccurate and corrupt data. Import Data > Merge Data Sets > Rebuild Missing Data > Standardize > Normalize > De-Duplicate > Verify & Enrich > Export Data |
| Big Data | |
| Data-Driven Organization | |
| Replication | Replication in backend engineering is the process of synchronously or asynchronously copying data from a primary database server to one or more replica servers to enhance data redundancy, improve read performance by distributing queries, and provide high availability in case of primary server failure. |
| Data Engineer | a type of software engineering that focuses on design, development large scale processing systems gather data from different sources. - Optimize databases for analyses. Remove corrupt files and repair the data pipeline. must know Linux, command line, Java, Python, or Scala |
| Data Scientist | mine data for patterns, model using statistics, clean outliers, comprehend predictive modeling using ML, monitor business processes and metrics |
| granularity | In a backend-specific context, granularity refers to the scope and functional size of an API endpoint, database transaction, or microservice, dictating the computation-to-communication ratio and the potential for independent deployment and scaling. |
| Slowly Changing Dimensions (SCD) | Slowly Changing Dimensions (SCDs) are a set of methodologies in data warehousing used to manage and track changes to attribute data in a dimension table over time, ensuring the historical accuracy of analytical reports without breaking the integrity of the data model. |
| surrogate keys | A surrogate key is a system-generated, non-business-meaningful unique identifier used as the primary key in a dimensional model to ensure stability, track history in Slowly Changing Dimensions, and optimize join performance between fact and dimension tables. |
| Natural Key | column(s) in a table that uniquely identify their row. Natural keys have a business meaning on their own. often is more than a single column, ex; the natural key for a table of addresses might be the five columns: street number, street name, city, state, and zip code |
| Polyglot Persistence | polyglot persistence: using multiple storage technologies in the same system, each tuned to its specific use case. |
| Upsert Pattern | An Upsert Pattern is a database operation that attempts to insert a new record into a table, but if a record with the same unique key already exists, it will update the existing record instead of failing the insertion. |
| high-throughput APIs | |
| data-heavy UIs | |
| WebSocket | a modern way to have persistent browser-server connections. data can be passed in both directions as “packets”, without breaking the connection and additional HTTP-requests. |
| Database | electronic system of storing data ex: 1. file system |
| Relational Database | Oracle, MySQL |
| What is a REST API? | it’s the agreed set of standardized ways that a particular piece of software can be used; the rules defined for its interaction with the wider world, which govern how other pieces of software can talk to a program and how it will respond. |
| Common HTTP / API Methods | GET, PUT, POST, DELETE |
| Shared State | any variable, object, or memory space that exists in a shared scope, or as the property of an object being passed between scopes. A shared scope can include global scope or closure scopes. Often objects are shared between scopes by adding properties to other objects |
| binding | Binding generally refers to a mapping of one thing to another. In the context of software libraries, bindings are wrapper libraries that bridge two programming languages |
| Monthly Active Users (MAU) | |
| Daily Active Users (DAU) | |
| path | the path is the part of a request URL after the hostname and port number |
| rate limit | calling your endpoint and requesting the same URL over and over thousands of times every single hour. This is where the concept of initiating a rate limit serves as a bright spot or ray of hope. An average rate limit would prevent the servers from going down with a CI server and offer users a clearer indication of how your API can be used more accurately. |
| Extract Transform Load (ETL) | Extract Data from text files, spreadsheets, DBs |
| The Infrastructure DBA | was in charge of setting up the database, configuring the storage and taking care of backups and replication. After setting up the database, the infrastructure DBA would pop up from time to time and do some "instance tuning", things like sizing caches. |
| The Application DBA | got a clean database from the infrastructure DBA, and was in charge of schema design: creating tables, indexes, constraints, and tuning SQL. The application DBA was also the one who implemented ETL processes and data migrations. In teams that used stored procedures, the application DBA would maintain those as well. |
| de-normalization | |
| request-response | 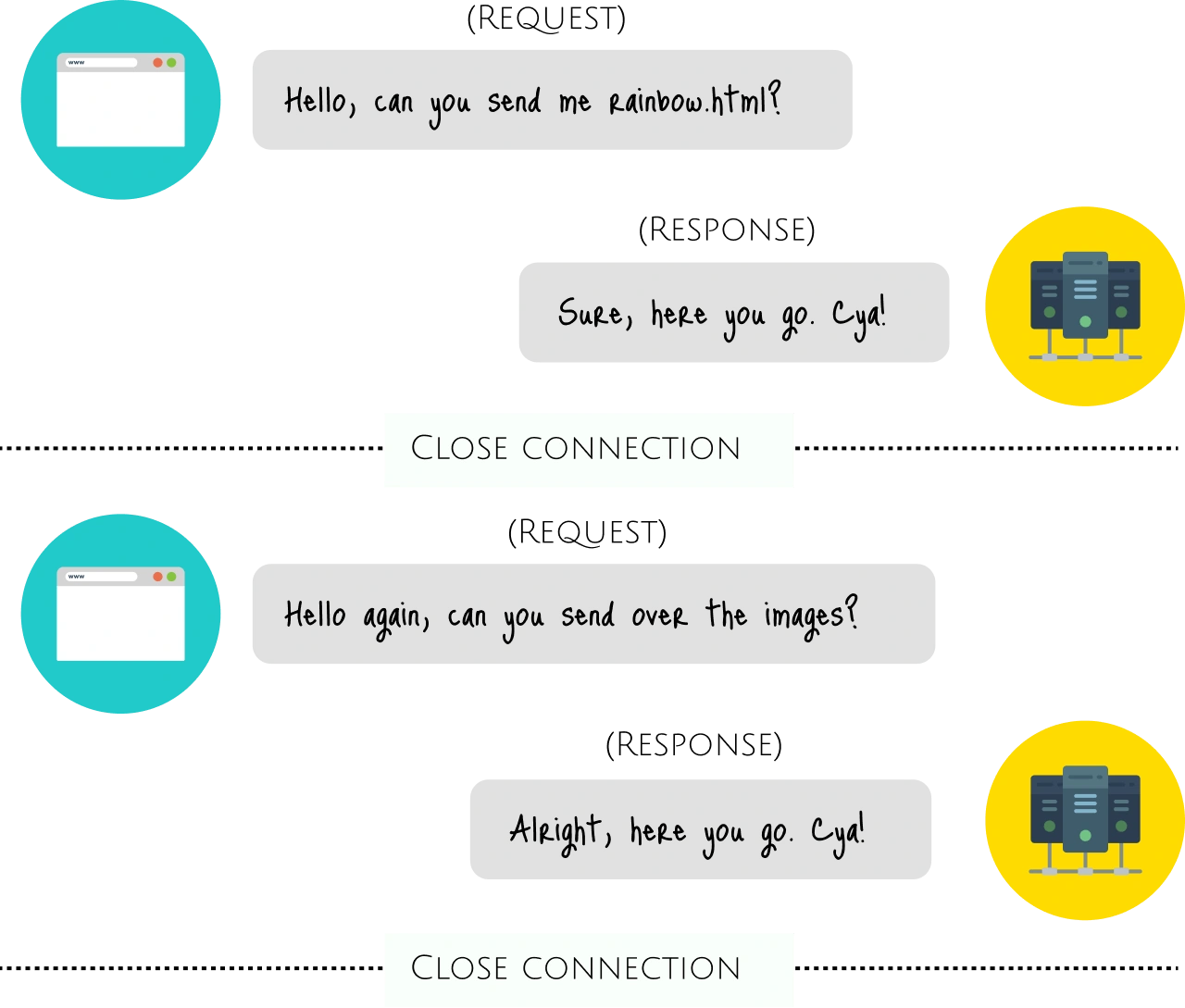 |
| scalability | Scalability is the capability of a system, network, or process to handle a growing amount of work, or its potential to be enlarged to accommodate that growth. |
| scalable database | available at all times. When the memory of the database is drained, or when it cannot handle multiple requests, it is not scalable. |
| Elasticity | Elasticity is the degree to which a system can adapt to workload changes by provisioning and de-provisioning resources in an on-demand manner, such that, At each point in time the available resources match the current demand as closely as possible. |
| Cloud Database | storing objects in a JSON like format. it doesn’t use tables or support queries like a traditional relational database |
| shards | Each shard is an independent database. divide the data set and distributes the data over multiple servers |
| Replication | Replication is to store backups of up-to-date data to overcome failure of nodes. |
| Streams | Streams are a fairly old concept in computing, originating from the early Unix days in the 1960s. A stream is a sequence of data coming over time from a source and running to a destination. The source can be of multiple types: files, the computer’s memory, or input devices like a keyboard or a mouse. Once a stream is opened, data flows in chunks from its origin to the process consuming it. Coming from a file, every character or byte would be read one at a time; coming from the keyboard, every keystroke would transmit data over the stream. The biggest advantage compared to loading all the data at once is that, in theory, the input can be endless and without limits. Coming from a keyboard, that makes total sense—why should anybody close the input stream you’re using to control your computer? Input streams are also called readable streams, indicating that they’re meant to read data from a source. On the other hand, there are outbound streams or destinations; they can also be files or some place in memory, but also output devices like the command line, a printer, or your screen. They’re also called writeable streams, meaning that they’re meant to store the data that comes over the stream. |
| Impedance Mismatch | |
| schema | |