Data Engineering

Backup Strategy
weigh the costs against the benefits secure storage for backup copy
Server Security
control who (Principles: Users, User Groups, 3rd Party APIs) can access what (Securables)
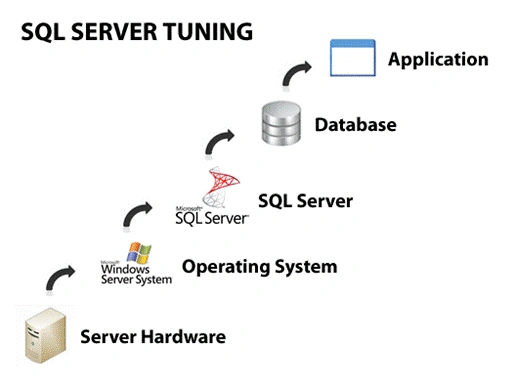
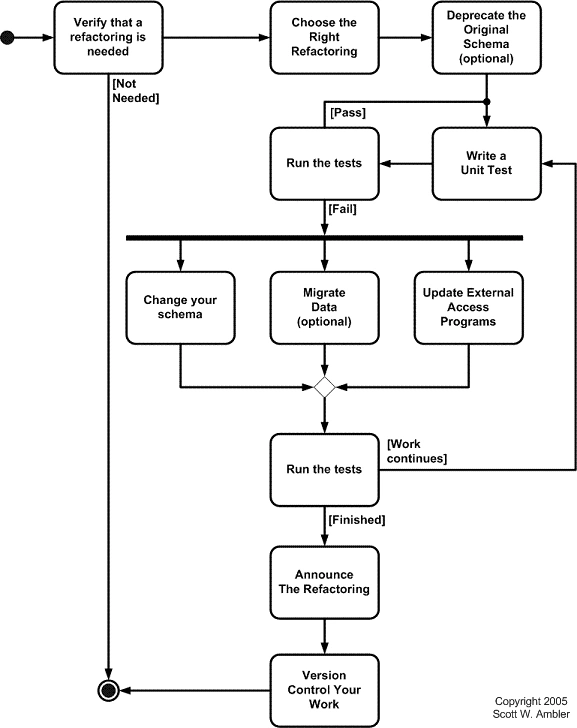
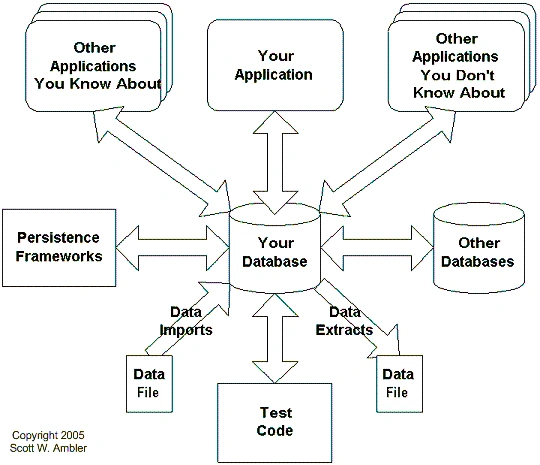
Structural Refactoring
- replace column
- drop column
- rename table
- rename column
- introduce calculated column
- introduce surrogate key
- replace one-to-many with associative table
- move columns
- merge columns
- merge tables
- drop tables
- drop view
- rename view
- replace Large Object with table
- replace surrogate key with natural key
- split column
- split table
Data Quality Refactoring
- make column non-nullable
- make column nullable
- drop default value
- add default value
- introduce column constraint
- drop column constraint
- move data
- replace type code with property flags
- introduce column format
- consolidate key strategy
- apply standard type
- apply standard codes
- add lookup table
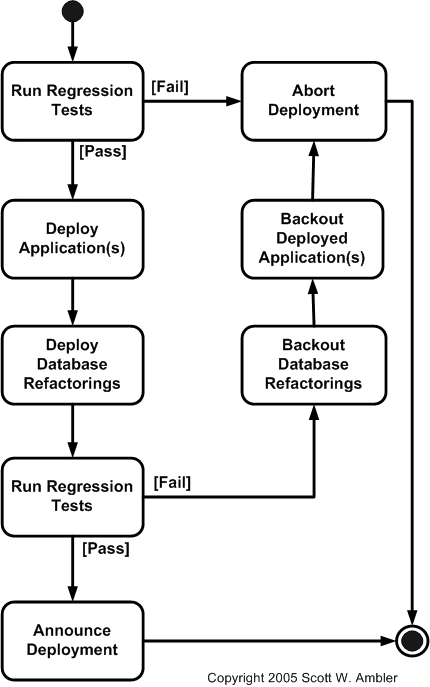
Referential Quality Refactoring
- add foreign key constraint
- introduce soft delete
- add trigger for calculated column
- drop foreign key constraint
- introduce cascading delete
- introduce hard delete
- introduce trigger for history
Database Performance Tuning
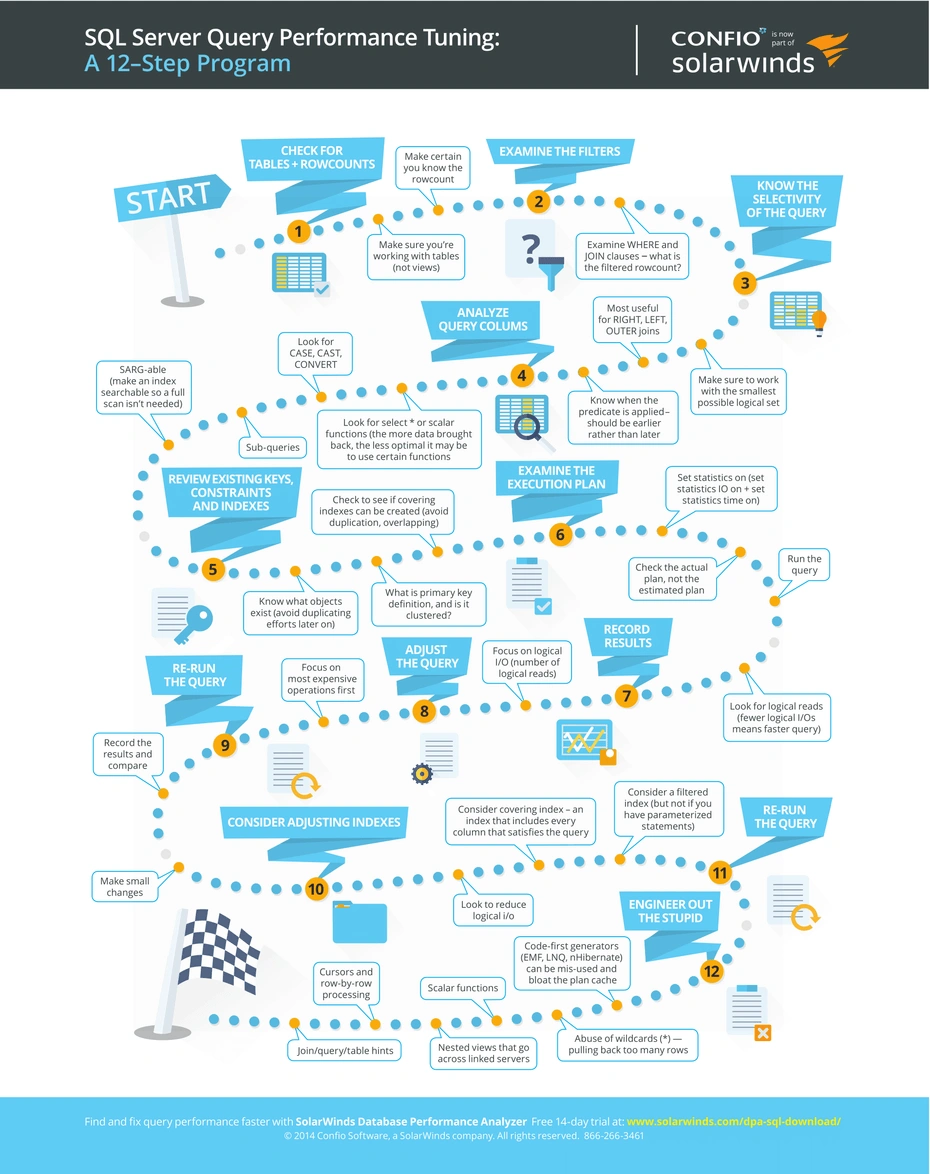
Optimizing SQL
-
Test Your Changes: Different databases handle SQL differently so it's not possible to lay down hard and fast rules that apply in every situation. What you can do, however, is look here for ideas to try and use an execution profiler to perform timing tests.
-
Check the Execution Plan: Most databases provide some facility to display the optimization strategy or plan that will be used. This will tell you if a fast index or primary key search will be used instead of a slow full table scan. For Sybase and Microsoft SQL Server use ISQL and the set showplan on command. For Watcom SQL use the plan() function as follows:
select plan ( 'select * from customer where id = 101' )
from sys.dummy;
Estimate 2 I/O operations Scan customer using primary key for rows where id equals 101 Estimate getting here 1 times
select plan ( 'select * from customer where fname = ''Beth''' )
from sys.dummy;
Estimate 10 I/O operations Scan customer sequentially Estimate getting here 126 times
-
Use Indexes: Carefully chosen indexes speed up SQL queries without slowing updates too much. Almost all tables can benefit from an index, and experience has shown that the "ideal index" is almost never the primary key (even though a primary key index may be required to preserve referential integrity). Be aware, however, that many databases only store the first few bytes (e.g., 10 for Watcom SQL) of each entry in the actual index. And with Watcom SQL it is not necessary to define indexes for primary and foreign keys because they are automatically created; if you use ERwin or a similar tool be sure to disable the creation of indexes for Watcom primary and foreign keys.
-
Avoid Not: If you can rewrite your queries to use the positive exists, in and like operators instead of not exists, not in or not like the database may be able to stop looking as soon as it finds an entry that satisfies the condition rather than proving that no entries exist.
-
Use Exists instead of Count: The DBMS may be able to stop looking as soon as it finds a row that satisfies the exists condition whereas with count it must process all matching rows. See also Exists Versus Count(*).
-
Try >= instead of >: If there is an index on column try select * from table where column >= 4 instead of where column > 3. Instead of looking in the index for the first row with column = 3 and then scanning forward for the first value that is > 3, the DBMS may jump directly to the first entry that is = 4.
-
Try Union instead of Or: The database may do a better job of optimizing two selects connected via union rather than one select with an or operator. For example,
select * from a, b where a.p = b.q
union
select * from a, b where a.x = b.y
may run faster than
select * from a, b where a.p = b.q or a.x = b.y
-
Avoid Where Column Like '%string': On the other hand where column like 'string%' may run quite quickly especially if there's an index on column.
-
Use Like Instead of Substr: If there is an index on column the database may process where column like 'x%' faster than where substr ( column, 1, 1 ) = 'x'.
-
Split Procedure to Create Then Select: If a stored procedure creates a temporary table and then selects from it, the database may not be able to optimize the select properly. Try moving the select to a second stored procedure which is called from the first.
-
Split Procedure to Turn a Variable Into a Parameter: The database may do a better job of optimizing where column = @var if @var is a stored procedure parameter rather than a local variable. Try moving the select to a second procedure which is called from the first procedure with @var passed as a parameter to the second procedure.
-
Consider Indexes for Max() and Min() The max ( column ) and min ( column ) aggregate functions may run faster if there is an index on column. Other restrictions may apply; try putting the function all by itself in a separate select rather than combining it with other expressions. The presence of a group by or where clause may also inhibit optimization. Make Indexes Unique When They Are: The database may do a better job with unique indexes than with non-unique ones. So if an index is truly unique, declare it as such.
-
Avoid Correlated Subselects: A correlated subselect is a nested select that refers to a column from the outer select. Here is an example that uses product.id as a correlation column to find all products that have no sales orders:
select product.id
from product
where not exists (
select sales_order_items.id
from sales_order_items
where sales_order_items.prod_id = product.id )
Correlated subselects can be very slow if the inner result set is re-selected for each and every candidate row in the outer result set. Alternative SQL can sometimes look rather bizarre but it's usually worth the effort. In Watcom SQL the following select runs almost 4 times faster by using an outer join instead of a correlated subselect:
select product.id
from product left outer join sales_order_items
on product.id = sales_order_items.prod_id
where IfNull ( sales_order_items.id, 1, 0 ) = 1
Hadoop HDFS Hadoop - enterprise open source projects
MapReduce - an algorithm
- the program distributes the workload into subtasks
- has some flaws, it's hard to write mapreduce jobs
Hive - Hive SQL to query data
Big Data Maturity
SEO
- Keywords
- Meta
- visitors
- clicks
Inbound Marketing
5 social media networks
- Google+
CMS
- blog
- comments
ERP
Enterprise resource planning (ERP) is the integrated management of main business processes, often in real time and mediated by software and technology. ERP is usually referred to as a category of business management software
Sales Charts
- information enables reactive improvements
- shopping cart metrics
- inventory metrics
- Filter charts by data, time,
Geolocation
- routes
Security
panel of green/red lights
- x509 certificates
- https
- ssl
- cors
Challenges
Consistency - latency
Data Deluge
- KPIs like unsubscribe rate
- use AI to get the insights you need
- specific metrics
- goals and objectives for marketing